管理がいちばん簡単な SQLite3 を念頭に。初期データを投入したら、そこから更新/削除がないことと、参照オンリーなので。
ちょっとしたデータ量なら何も考えずに INSERT 文を投入すればいいのだが、さすがに 10 万行、100 万行、1000 万行も同様にいくまい。
CSV ファイルまたは TSV ファイルを SQLite3 の .import コマンドで投入するほうが早いらしい。
あるいは CSV ファイルまたは TSV ファイルを tar.gz 圧縮した状態で、Python 経由で投入する方法もいいらしい。
テーブル定義
create table NOTES( MUSIC_ID text, MODE text, DIFFICULT text, MEASURE integer, SIDE integer, NOTE_INDEX integer, ELAPSED_MS integer, COMBO integer, NORMAL text, MIRROR text, FLIP text, FLIP_MIRROR text ) ; create index IDX_NOTES_NORMAL on NOTES (NORMAL) ;
列名と格納される値の対応表は以下の通り。
| MUSIC_ID | 曲を識別する文字列(ASCII 8 文字以内) |
| MODE | 'DP' 固定 |
| DIFFICULT | 'N', 'H', 'A', 'L'のいずれか |
| MEASURE | 小節番号 (整数) |
| SIDE | 1, 2のいずれか |
| NOTE_INDEX | 通し番号 |
| ELAPSED_MS | 譜面上の経過時間(ミリ秒) |
| COMBO | 切り出した譜面におけるコンボ数 |
| NORMAL | 正規譜面 |
| MIRROR | ミラー譜面 |
| FLIP | FLIP正規譜面 |
| FLIP_MIRROR | FLIPミラー譜面 |
ここで正規譜面、ミラー譜面、FLIP正規譜面、FLIPミラー譜面は、「鍵盤=1~7」「ターンテーブル=S」「同時押し=隣接して記述(例:"135", "S1")」「半角スペースは非同時押し(例:上り大階段="1 2 3 4 5 6 7 S")」のように記述する。
INSERT 文を 800 万行投入
INSERT 文のサンプル
insert into NOTES(MUSIC_ID, MODE, DIFFICULT, MEASURE, SIDE, NOTE_INDEX, ELAPSED_MS, COMBO, NORMAL, MIRROR, FLIP, FLIP_MIRROR) values ('viridian', 'DP', 'A', 2, 1, 5, 2329, 8, '3 5 3 5 4 S 6 1', '5 3 5 3 4 S 2 7', '3 5 3 5 4 S 6 1', '5 3 5 3 4 S 2 7'); insert into NOTES(MUSIC_ID, MODE, DIFFICULT, MEASURE, SIDE, NOTE_INDEX, ELAPSED_MS, COMBO, NORMAL, MIRROR, FLIP, FLIP_MIRROR) values ('viridian', 'DP', 'A', 2, 1, 6, 2422, 8, '5 3 5 4 S 6 1 4', '3 5 3 4 S 2 7 4', '5 3 5 4 S 6 1 4', '3 5 3 4 S 2 7 4'); insert into NOTES(MUSIC_ID, MODE, DIFFICULT, MEASURE, SIDE, NOTE_INDEX, ELAPSED_MS, COMBO, NORMAL, MIRROR, FLIP, FLIP_MIRROR) values ('viridian', 'DP', 'A', 2, 1, 7, 2515, 8, '3 5 4 S 6 1 4 16', '5 3 4 S 2 7 4 27', '3 5 4 S 6 1 4 16', '5 3 4 S 2 7 4 27');
SQL ファイルは、楽曲別、譜面種別別に分かれていて、合計 6157 ファイルある。
$ sqlite3 notes.db < schema.sql $ sqlite3 notes.db < sql/1/511_hs-DPN.sql ... $ sqlite3 notes.db < sql/29/xyndrome-DPA.sql
sql ファイル数は 3000 で、24 時間以上かかった。
残り sql ファイル数が 3157 あり、同様に実行するとおそらく 25 時間ほどかかり、推定総実行時間は 50 時間弱と考えられる。
IMPORT 文で 1600 万行投入
csv ファイルのサンプル
viridian,DP,A,2,1,5,2329,8,3 5 3 5 4 S 6 1,5 3 5 3 4 S 2 7,3 5 3 5 4 S 6 1,5 3 5 3 4 S 2 7 viridian,DP,A,2,1,6,2422,8,5 3 5 4 S 6 1 4,3 5 3 4 S 2 7 4,5 3 5 4 S 6 1 4,3 5 3 4 S 2 7 4 viridian,DP,A,2,1,7,2515,8,3 5 4 S 6 1 4 16,5 3 4 S 2 7 4 27,3 5 4 S 6 1 4 16,5 3 4 S 2 7 4 27
CSV ファイルは、楽曲別、譜面種別別に分かれていて、合計 6157 ファイルある。
$ sqlite3 notes.db < schema.sql $ sqlite3 notes.db -separator , ".import csv/1/511_hs-DPN.csv NOTES" ... $ sqlite3 notes.db -separator , ".import csv/29/xyndrome-DPA.csv NOTES"
csv ファイル数は 6157 で、3 時間以内で完走した。
IMPORT 文で、人力パーティショニング 1600 万行投入
NOTES 表の COMBO 列は、値が1~8のいずれかを取る。この値をもとに人力パーティショニングを行う、すなわち出力 CSV ファイルを選択する。その結果、インポート対象 csv ファイル 1 つにつき、db ファイル 1 つの構成とする。
$ sqlite3 notes-1.db < schema.sql ... $ sqlite3 notes-8.db < schema.sql $ sqlite3 -separator , notes-1.db ".import csv/notes-1.csv NOTES" ... $ sqlite3 -separator , notes-8.db ".import csv/notes-8.csv NOTES"
csv ファイル数は 8 で、16 分で完走した。
データ件数
$ ls -1 notes-?.csv | xargs wc -l 449832 notes-1.csv 4677906 notes-2.csv 4665600 notes-3.csv 4653294 notes-4.csv 4640988 notes-5.csv 4628682 notes-6.csv 4616376 notes-7.csv 4604070 notes-8.csv 32936748 合計 $
ファイルサイズ
インポート元 csv ファイル
$ ls -lahF notes-?.csv -rw-rw-r-- 1 python python 18M 5月 10 17:06 2022 notes-1.csv -rw-rw-r-- 1 python python 200M 5月 10 17:06 2022 notes-2.csv -rw-rw-r-- 1 python python 238M 5月 10 17:06 2022 notes-3.csv -rw-rw-r-- 1 python python 276M 5月 10 17:06 2022 notes-4.csv -rw-rw-r-- 1 python python 313M 5月 10 17:06 2022 notes-5.csv -rw-rw-r-- 1 python python 350M 5月 10 17:06 2022 notes-6.csv -rw-rw-r-- 1 python python 387M 5月 10 17:06 2022 notes-7.csv -rw-rw-r-- 1 python python 423M 5月 10 17:06 2022 notes-8.csv
SQLite3 データベースファイル
$ ls -lahF notes-?.db -rw-r--r-- 1 lmtak lmtak 26M 5月 10 17:14 2022 notes-1.db -rw-r--r-- 1 lmtak lmtak 291M 5月 10 17:15 2022 notes-2.db -rw-r--r-- 1 lmtak lmtak 343M 5月 10 17:16 2022 notes-3.db -rw-r--r-- 1 lmtak lmtak 395M 5月 10 17:17 2022 notes-4.db -rw-r--r-- 1 lmtak lmtak 447M 5月 10 17:20 2022 notes-5.db -rw-r--r-- 1 lmtak lmtak 497M 5月 10 17:23 2022 notes-6.db -rw-r--r-- 1 lmtak lmtak 545M 5月 10 17:26 2022 notes-7.db -rw-r--r-- 1 lmtak lmtak 597M 5月 10 17:30 2022 notes-8.db $
SQL 実行速度
notes-1.db
$ time sqlite3 notes-1.db "select SIDE, NORMAL, count(*) CNT from NOTES group by SIDE, NORMAL order by CNT" 1|12345|1 1|12347|1 1|1235|1 (中略) 2|13|23706 1|15|27463 1|13|32914 real 0m1.299s user 0m1.252s sys 0m0.046s
一番件数の多いレコードについて取得
$ time sqlite3 notes-1.db "select * from NOTES where NORMAL = '13' and SIDE = 1" > ./tmp.txt real 0m0.216s user 0m0.190s sys 0m0.025s
notes-2.db
$ time sqlite3 notes-2.db "select SIDE, NORMAL, count(*) CNT from NOTES group by SIDE, NORMAL order by CNT" 1|1 1234|1 1|1 1245|1 1|1 1347|1 (中略) 1|3 5|78033 2|3 5|79839 1|1 1|100925 real 0m16.089s user 0m14.983s sys 0m1.089s
一番件数の多いレコードについて取得
$ time sqlite3 notes-2.db "select * from NOTES where NORMAL = '1 1' and SIDE = 1" > ./tmp.txt real 0m0.679s user 0m0.593s sys 0m0.085s
notes-3.db
$ time sqlite3 notes-2.db "select SIDE, NORMAL, count(*) CNT from NOTES group by SIDE, NORMAL order by CNT" 1|1 13|1 1|1 135|1 1|1 24|1 1|1 46|1 1|1 7|1 1|1 1 126|1 1|1 1 346|1 (中略) 2|1 1 1|34684 1|S S S|37157 1|1 1 1|60071 real 0m26.184s user 0m20.177s sys 0m6.000s
1 SP SP 13あたりのデータは壊れてるな……
$ time sqlite3 notes-3.db "select * from NOTES where NORMAL = '1 1 1' and SIDE = 1" > ./tmp.txt real 0m0.400s user 0m0.347s sys 0m0.052s
notes-4.db
$ time sqlite3 notes-4.db "select SIDE, NORMAL, count(*) CNT from NOTES group by SIDE, NORMAL order by CNT" 1|1 1 7|1 1|1 13 3|1 1|1 135 157|1 (中略) 2|S S S S|25312 1|S S S S|27551 1|1 1 1 1|43101 real 0m46.685s user 0m28.024s sys 0m13.961s
$ time sqlite3 notes-4.db "select * from NOTES where NORMAL = '1 1 1 1' and SIDE = 1" > ./tmp.txt real 0m0.290s user 0m0.259s sys 0m0.030s
1 SP SP SP 135 SP 157を検索してみると、
$ sqlite3 notes-4.db "select * from notes where NORMAL = '1 135 157'" poodle|DP|L|23|1|163|1125|4|1 135 157|7 357 137|1 135 157|7 357 137
POODLE (DPL) の 23 小節目とのことで、
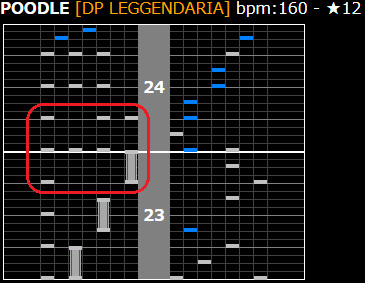
https://textage.cc/score/12/poodle.html?DXC00~23-24
ここ、かも? チャージノーツの展開部に失敗してそう。
notes-5.db
$ time sqlite3 notes-5.db "select SIDE, NORMAL, count(*) CNT from NOTES group by SIDE, NORMAL order by CNT" 1|1 1 1|1 1|1 1 1 35|1 1|1 1 1 4|1 (中略) 2|S S S S S|19784 1|S S S S S|21556 1|1 1 1 1 1|32896 real 0m55.458s user 0m31.818s sys 0m16.859s
$ time sqlite3 notes-5.db "select * from NOTES where NORMAL = '1 1 1 1 1' and SIDE = 1" > ./tmp.txt real 0m0.230s user 0m0.197s sys 0m0.032s
notes-6.db
$ time sqlite3 notes-6.db "select SIDE, NORMAL, count(*) CNT from NOTES group by SIDE, NORMAL order by CNT" 1|1 1 1 3|1 1|1 1 6 2|1 1|1 1 6 5|1 (中略) 2|S S S S S S|16111 1|S S S S S S|17586 1|1 1 1 1 1 1|26186 real 0m57.705s user 0m35.363s sys 0m18.275s
$ time sqlite3 notes-6.db "select * from NOTES where NORMAL = '1 1 1 1 1 1' and SIDE = 1" > ./tmp.txt real 0m0.181s user 0m0.161s sys 0m0.020s
notes-7.db
$ time sqlite3 notes-7.db "select SIDE, NORMAL, count(*) CNT from NOTES group by SIDE, NORMAL order by CNT" | head 1|1|1 1|1 5|1 1|1 5 4 6 1|1 (中略) 2|S S S S S S S|13378 1|S S S S S S S|14611 1|1 1 1 1 1 1 1|20967 real 1m3.064s user 0m39.274s sys 0m20.126s
$ time sqlite3 notes-7.db "select * from NOTES where NORMAL = '1 1 1 1 1 1 1' and SIDE = 1" > ./tmp.txt real 0m0.146s user 0m0.126s sys 0m0.018s
notes-8.db
1||1 1|1 5 5|1 1|1 5 4 6 1 1|1 (中略) 2|S S S S S S S S|11319 1|S S S S S S S S|12367 1|1 1 1 1 1 1 1 1|16802 real 1m7.157s user 0m42.700s sys 0m20.838s
ついに空文字列が出てきた。面白い
$ time sqlite3 notes-8.db "select * from NOTES where NORMAL = '1 1 1 1 1 1 1 1' and SIDE = 1" > ./tmp.txt real 0m0.121s user 0m0.105s sys 0m0.015s
カーディナリティーが高いほど、検索時間は減るのは直観通りだな。